
Understanding the Evidence Pyramid Beyond the Hierarchy
Moving beyond levels of evidence to understand quality, context, and application

We, as healthcare professionals, make clinical decisions that rely on evidence from various sources. However, not all evidence is considered equally trustworthy. Some forms of evidence are seen as more rigorous, less biased, or more clinically informative than others. As a result, healthcare education and research often rely on frameworks to organise evidence according to perceived strength.
One of the most widely used of these frameworks is the evidence pyramid (see figure 1).
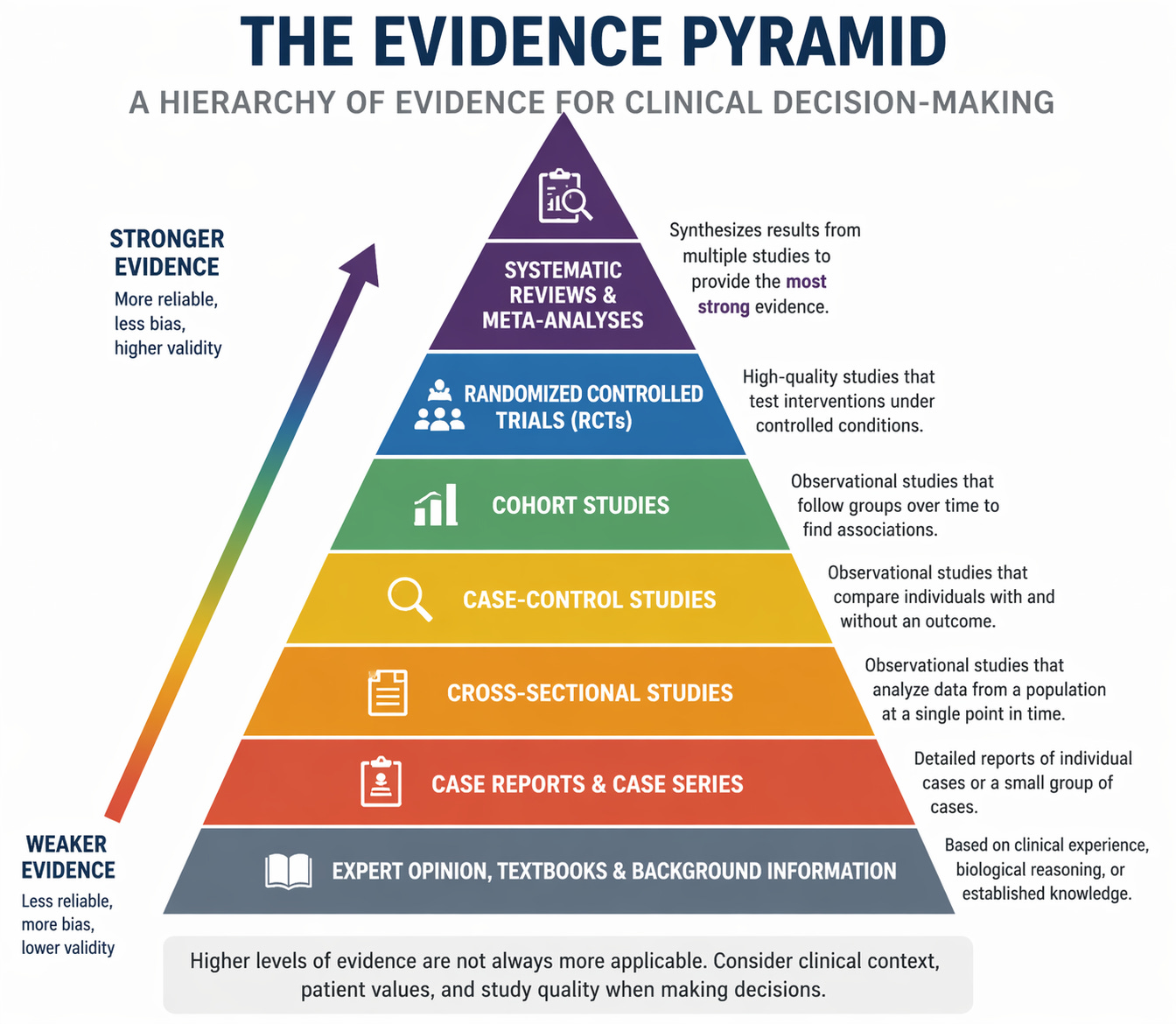
The evidence pyramid has become a ubiquitous teaching tool, presenting a visual framework for understanding research quality. However, this seemingly simple hierarchy masks significant complexities and limitations that every clinician and researcher should understand.
This post will explain the traditional evidence pyramid while critically examining its fundamental assumptions, limitations, and appropriate applications.
The Foundation: Where Clinical Knowledge Begins
At the base of the pyramid, we find Background Information & Expert Opinion. This includes clinical textbooks, like ClinicalKey and AccessMedicine, which provide foundational medical knowledge and synthesised guidance for clinical practice.
What this level offers: These resources excel at providing comprehensive overviews of diseases, pathophysiology, and standard management approaches. They contextualise research findings within broader clinical frameworks and offer practical guidance when high-quality research is unavailable or when integrating multiple evidence streams. Expert consensus statements can be particularly valuable for rare conditions where formal research is impractical or for rapidly evolving situations where published research lags behind clinical experience.
The critical limitation: Expert opinion can be influenced by cognitive biases, conflicts of interest, outdated training, and local practice patterns. What experts believe to be true may not align with empirical evidence. The history of medicine is filled with expert-endorsed practices later proven harmful or ineffective through rigorous research.
When to use this level: Background resources are ideal for learning foundational concepts, understanding disease mechanisms, and gaining initial orientation to a clinical problem. However, they should not be the endpoint of evidence-seeking for consequential clinical decisions.
Building Upward: Primary Research Studies
Moving up the pyramid, we encounter individual research studies, traditionally arranged by their methodological rigour:
Case Reports and Case Series
What these studies provide: These publications document detailed observations of individual patients or small groups experiencing unusual presentations, rare diseases, novel interventions, or unexpected adverse events. They generate hypotheses and alert the medical community to emerging patterns.
How to apply them: Case reports shine when identifying rare adverse drug reactions, unusual disease presentations, or potential new syndromes. A cluster of case reports describing similar unusual events can signal an important pattern worthy of systematic investigation. They provide rich clinical detail that helps clinicians recognise similar cases in their own practice.
Critical limitations: The plural of anecdote is not data. Case series lack comparison groups, cannot establish causation, and are heavily susceptible to publication bias—unusual or positive outcomes are far more likely to be reported than typical or negative ones. The natural course of disease, regression to the mean, and placebo effects cannot be distinguished from true treatment effects.
Case-Control Studies
What these studies provide: These retrospective studies compare people who have developed an outcome (cases) with those who have not (controls), looking backward to identify differences in exposures or risk factors. They are particularly efficient for studying rare diseases or outcomes with long latency periods.
How to apply them: Case-control studies are valuable for investigating potential risk factors for rare conditions, generating hypotheses about disease causation, and conducting preliminary investigations before committing resources to prospective studies. They can identify strong associations relatively quickly and inexpensively.
Critical limitations: Recall bias is a major concern when people with a disease may remember exposures differently from healthy controls. Selection of appropriate controls is challenging and can dramatically affect results. These studies cannot determine disease incidence or prevalence. Temporal relationships can be unclear, making it difficult to establish whether the exposure preceded the outcome. Confounding variables may create spurious associations.
Cohort Studies
What these studies provide: These prospective or retrospective studies follow groups of people over time, comparing outcomes between those exposed and unexposed to a risk factor or intervention. They maintain the natural timeline of disease development and can examine multiple outcomes from a single exposure.
How to apply them: Cohort studies are excellent for studying prognosis, natural history of disease, and situations where randomisation would be unethical or impractical. They can establish temporal relationships between exposures and outcomes, calculate incidence rates and relative risks, and examine rare exposures. Large population-based cohorts can provide real-world evidence about interventions in diverse populations.
Critical limitations: Prospective cohort studies require substantial time and resources. Loss to follow-up can introduce bias if those who drop out differ systematically from those who remain. While better than case-control studies at reducing confounding, cohort studies remain vulnerable to unmeasured confounders. Participants who choose different exposures may differ in other important ways, creating confounding by indication.
Randomised Controlled Trials (RCTs)
What these studies provide: RCTs use randomisation to allocate participants to intervention or control groups, minimising selection bias and balancing both measured and unmeasured confounding factors. They represent the most rigorous approach to establishing causal relationships between interventions and outcomes.
How to apply them: When properly designed and executed, RCTs provide the strongest evidence for treatment efficacy. When reading trials, critically appraise the sample sizes, randomisation and allocation concealment, blinding where feasible, intention-to-treat analysis, and clinically relevant outcomes. Pay attention to the study population. Does it resemble your patients? Consider whether the intervention as delivered in the trial is feasible in your setting.
Critical limitations: RCTs are not always feasible, ethical, or appropriate. They can be prohibitively expensive and time-consuming. Strict eligibility criteria often create highly selected populations that don’t reflect real-world clinical practice, limiting generalizability. Short follow-up periods may miss long-term effects or rare adverse events. The controlled trial environment may not replicate real-world adherence or implementation. For some questions, like the harms of smoking or the benefits of parachutes, the RCTs would be unethical or unnecessary.
The Apex: Synthesised Evidence
At the top of the pyramid sit synthesis and appraisal of existing research:
Critically Appraised Sources
What these resources provide: Services like UpToDate, Dynamed, Clinical Evidence, PEDro, ACP Journal Club, and Essential Evidence Plus employ expert teams to continuously monitor medical literature, appraise study quality, and synthesise findings into actionable clinical recommendations. They provide pre-digested, regularly updated summaries that save clinicians time.
How to apply them: These resources are invaluable at the point of care when you need a quick, evidence-based answer to a clinical question. They excel at integrating evidence from multiple studies and providing graded recommendations. Use them as a starting point for clinical decision-making, but recognise that they represent someone else’s interpretation of the evidence.
Critical limitations: Even expert appraisals reflect the biases and judgment of their authors. These resources may lag behind the most recent research. The process of simplifying complex evidence into clinical recommendations necessarily involves subjective decisions. Conflicts of interest and industry influence can sometimes affect recommendations. The evidence supporting different recommendations varies considerably; not all guidance carries equal weight.
Systematic Reviews
What these studies provide: Systematic reviews use explicit, reproducible methods to identify, select, and critically appraise all relevant research on a specific question. They provide comprehensive overviews of the available evidence, identify gaps in knowledge, and assess consistency across studies.
How to apply them: A well-conducted systematic review offers a comprehensive landscape of research on a topic. When reading a systematic review, the most important thing to check is the search strategy. Was it comprehensive? If it were not, it would have missed key evidence. Evaluate the inclusion criteria—are they appropriate for the question? Assess the quality appraisal of the review, whether they critically evaluate the included studies. Consider whether the findings are consistent or heterogeneous.
Critical limitations: Systematic reviews are only as good as the studies they include—synthesising poor-quality research doesn’t produce high-quality evidence. Publication bias means that negative studies are often missing, leading to overly optimistic conclusions. Different reviews on the same topic sometimes reach different conclusions based on varying inclusion criteria or quality assessments. Reviews can become outdated quickly in rapidly evolving fields. The scope and focus of the review question determine what gets included and excluded.
Meta-Analysis
What these studies provide: Meta-analyses go beyond systematic reviews by statistically pooling results from multiple studies, increasing statistical power and potentially providing more precise effect estimates. They can detect effects that individual studies were too small to identify and explore reasons for variation in results across studies.
How to apply them: Meta-analyses are most valuable when combining multiple high-quality studies addressing the same question in similar populations. Examine the forest plots do confidence intervals overlap, suggesting consistent results? Check for heterogeneity statistics; a high heterogeneity suggests important differences between studies. Look at subgroup analyses and sensitivity analyses—do results hold up when analyzed different ways?
Critical limitations: The adage “garbage in, garbage out” applies powerfully here. Statistical pooling of flawed studies produces flawed results. Combining studies with different populations, interventions, or outcome measures may be methodologically inappropriate. Publication bias affects meta-analyses particularly strongly. Different meta-analyses on the same topic can reach contradictory conclusions based on differing inclusion criteria or statistical methods. The apparent precision of a meta-analysis can be misleading if based on heterogeneous or biased studies.
Critical Limitations: When the Pyramid Breaks Down
The traditional evidence pyramid is not a universal truth—it is a simplified teaching tool with significant limitations that can mislead if applied uncritically.
The Question-Type Problem: One Pyramid Cannot Fit All
The fundamental flaw: The pyramid shown is designed for questions about therapeutic interventions—does treatment X improve outcome Y? However, clinical practice involves many other types of questions, each requiring different research designs.
For diagnostic questions (”How accurate is this test?”): Cross-sectional studies comparing an index test to a reference standard are the appropriate design. RCTs are generally not feasible or necessary for diagnostic accuracy. A case-control study might actually provide better evidence than an RCT for this question type. The hierarchy completely changes—what matters is whether the study used an appropriate reference standard, included a representative spectrum of patients, and avoided verification bias.
For prognostic questions (”What is the likely course of this disease?”): Cohort studies that follow patients over time provide the strongest evidence. RCTs are often inappropriate because you cannot randomise patients to have different prognoses. Case series with long-term follow-up can provide valuable prognostic information that RCTs cannot. The traditional pyramid actively misleads here.
For questions of harm or aetiology (”Does exposure X cause disease Y?”): RCTs are often unethical or impractical. You cannot randomise people to smoke cigarettes or be exposed to asbestos. Here, well-designed cohort studies and case-control studies provide the best available evidence. The Bradford Hill criteria for causation become more relevant than the position on the evidence pyramid.
For questions about prevalence or incidence (”How common is this condition?”): Cross-sectional surveys and well-designed cohort studies provide the appropriate evidence. RCTs and systematic reviews are not the right tools for these questions.
For rare adverse events: Case reports and pharmacovigilance databases may provide the only available evidence, making them more valuable than RCTs that are too small or too short to detect rare harms.
Quality Matters More Than Design
A well-conducted lower-level study beats a poorly conducted higher-level study. A rigorous cohort study with careful control of confounding may provide better evidence than a small, poorly randomised RCT with high attrition and selective outcome reporting. A systematic review that includes only low-quality studies or suffers from publication bias does not automatically provide better evidence than a single well-designed RCT.
Critical appraisal skills are essential: Understanding the hierarchy is useful, but it cannot replace the ability to critically evaluate individual studies. Risk of bias assessment, evaluation of directness and applicability, and judgment about clinical importance are all essential skills that cannot be reduced to a position on a pyramid.
The Systematic Review Problem
Not all systematic reviews are created equal: The explosive growth of systematic reviews has led to variable quality, redundancy, and sometimes contradictory conclusions. Some systematic reviews are outdated before publication. Others include inappropriate studies or the use of flawed statistical methods. The mere fact that something is labelled a “systematic review” does not guarantee quality or relevance.
Conflicts of interest: Industry-funded systematic reviews sometimes reach different conclusions than independent reviews on the same topic. Meta-analyses can be manipulated through strategic inclusion/exclusion of studies, choice of statistical methods, or selective outcome reporting.
Context, Applicability, and the Individual Patient
Even perfect evidence about populations tells you probabilities, not certainties, about the individual patient in front of you.
Efficacy vs. effectiveness: RCTs typically measure efficacy (does it work under ideal conditions?) rather than effectiveness (does it work in real-world practice?). Treatments proven effective in RCTs often fail in routine care due to adherence issues, implementation barriers, resource constraints, or population differences.
External validity: The patients in research studies frequently differ from your patients. Age, sex, comorbidities, disease severity, ethnicity, socioeconomic status, and health literacy all affect how evidence applies. A hierarchy based on internal validity (bias minimisation) says nothing about external validity (generalizability).
Patient values and preferences: The “best” evidence is meaningless if it doesn’t align with what matters to your patient. Some patients prioritise length of life; others prioritise quality of life. Some accept high risk for small potential benefit; others don’t. The pyramid cannot tell you how to integrate evidence with individual patient values.
The Danger of Uncritical Application
The evidence pyramid’s greatest harm comes from uncritical application:
Dismissing valuable evidence: Clinicians may inappropriately dismiss well-conducted cohort studies or case-control studies simply because they’re “lower” on the pyramid, even when they provide the best available evidence for the question at hand
Overvaluing flawed syntheses: Clinicians may uncritically accept systematic reviews or meta-analyses without evaluating their quality, simply because they’re at the pyramid’s apex
Asking the wrong question: The pyramid encourages framing all clinical questions as intervention questions, when many questions are actually about diagnosis, prognosis, or harm
Ignoring applicability: The pyramid suggests that study design determines evidence quality, obscuring the critical question of whether the evidence applies to your specific clinical context
Undermining clinical judgment: The pyramid implies that research evidence alone determines best practice, marginalising clinical expertise and patient preferences.
What the Pyramid Gets Right
Despite these critiques, the evidence pyramid does convey important truths:
Not all evidence is equal: Research quality varies, and some study designs are more prone to bias than others
Synthesis is valuable: Well-conducted systematic reviews provide efficient access to synthesised evidence
Randomisation reduces bias: For intervention questions, RCTs minimise selection bias and confounding
Critical appraisal matters: Filtered resources save time by providing pre-appraised evidence
These insights remain valid. The problem is not that the pyramid is entirely wrong—it’s that it’s incomplete, oversimplified, and frequently misapplied.
Conclusion: A Tool for Thinking, Not a Substitute for Thinking
The evidence pyramid is a useful teaching tool for introducing concepts of research quality and evidence appraisal. It efficiently conveys that case reports carry less weight than controlled trials, and that synthesised evidence is more efficient than reading dozens of primary studies.
But the pyramid is not and cannot be a comprehensive guide to evidence evaluation. It cannot replace:
Understanding your question type and matching it to appropriate study designs
Critical appraisal of individual studies regardless of their design
Judgment about applicability to your specific clinical context
Integration of evidence with clinical expertise and patient values
Tolerance for uncertainty and acknowledgement of evidence gaps
The evidence pyramid should be a starting point for thinking about evidence quality, not an endpoint that substitutes for thinking.
In our next post, we’ll explore how to actually apply the evidence pyramid appropriately—when it’s useful, how to adapt it for different question types, and how to integrate it with critical appraisal skills and clinical judgment.
Key Takeaways
The traditional evidence pyramid is designed for intervention questions and actively misleads for diagnostic, prognostic, harm, and prevalence questions
The question type must be identified before applying any evidence hierarchy
Systematic reviews vary enormously in quality and can be biased, outdated, or inappropriate
Evidence about populations provides probabilities, not certainties, about individual patients
The pyramid is a teaching tool, not a rigid rule—it should guide your thinking, not replace it
The most important question is not “Where does this study sit on the pyramid?” but rather “Does this evidence appropriately address my clinical question, is it trustworthy, and does it apply to my patient?”
Coming in Part 2: How to Actually Use the Evidence Pyramid—A Practical Framework for Matching Study Designs to Clinical Questions
Thanks for Reading!
Ammar Suhail